2. "Implementing QuantLib"の和訳
Chapter-VII The Tree Framework: Tree を使った価格モデルのフレームワーク
7.2 Tree および Tree-Based Lattice
7.2.1 Treeクラスのテンプレート
今説明した通り、Treeクラスはその‘構造’についての情報を提供します。Treeの構造とは、①各Level上のNode数 (訳注:以下、原書に従い、Lattice上の各時間軸を“Level”と呼び、各Level上の離散的な確率変数の値を格納する場所として“Node”を使う) と、②ひとつ前の Level の各 Node から、次の Level のどの Node に分岐していくのか、③そして、その分岐先Nodeへの遷移確率、によって特定されます。
こういった情報をやり取りするために、当初選択されたインターフェース (下記 Listing 7.6 に示します)は、各 Node を示すインデックスをベースにしたものでした。すなわち、各Node は Nodeクラスのインスタンスの集まりとして設計されていませんでした。従って、Tree構造は、そのサイズが増加可能な、一連の配列で表現されていました (そのように実装されたわけではありませんので注意して下さい)。各 Node はその配列の要素を示す"インデックス"で特定されていました。この方法は、異なる Tree構造を実装する際に、より柔軟に対応できます。ある Treeクラスでは各 Node の配列を保持している一方、別の Treeクラスでは、必要に応じてインデックスを計算で求める方法を取っていました。QuantLibライブラリーでは、3項モデルが前者の方法で、2項モデルが後者の方法で実装されています。両方とも、後ほど説明します。
Listing 7.6:Original interface of Tree class
class Tree {
public:
Tree(Size columns);
virtual ~Tree();
Size columns() const;
virtual Size size(Size i) const = 0;
virtual Real underlying(Size i, Size j) const = 0;
virtual Size branches() const = 0;
virtual Size descendant(Size i, Size j, Size branch) const = 0;
virtual Real probability(Size i, Size index, Size branch) const = 0;
}; インターフェースで示されているメソッド群が、Treeクラスの構造をすべて表現しています。columns( )メソッドは、Tree構造の中の Level数 (訳注:原文に従い、離散時間における各時点を示すものとして、‘Level’を使います) を返します。このクラスを当初設計した者は、Tree の時間軸を左から右へ進むような構図を想定して設計しており、Treeの階層の数も左から右に増加すると想定していたようです。(訳注:従って、縦の線が特定の時点を示すもので column( ) というメソッド名にした。一方、著者の方は、後に出てくる Tree の構図でわかるとおり、Tree を下から上に分岐させていく構図を想定しているので、このような説明が入っていると思います) 仮にインターフェースの内容を変える事になれば、まずメソッド名をもっと中立的な (訳注: Treeの構図における分岐先の方向が上下でも左右でも使える) 名前 (例えばsize( )とか) にするでしょう。
実は、size( )メソッドの名前は既に他のメソッドで使われており、そのメソッドは i 番目の Level にある Node 数を返すものです。underlying( )メソッドは、2種類のインデックス i と j を引数で取り、i 番目のLevelにある j 番目の Node における対象資産の値を返します。
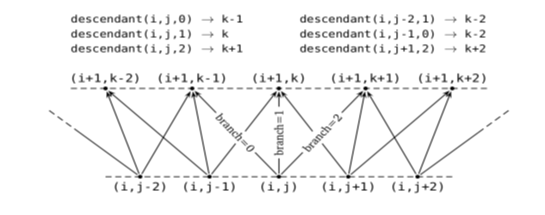
残りのメソッド群は、Tree の分岐構造を取り扱います。 branches( )は、各 Node における分岐の数を返します (2項モデルであれば2、3項モデルなら3)。このメソッドは引数を取りませんが、その理由は、分岐数は基本的に定数になるという前提の為です。descendant( )メソッドは、ある Node からの分岐先の Node インデックスを特定します。このメソッドは引数として、Level を示すインデックス i、Node を示すインデックス j、および分岐先のインデックス (訳注: 2項Treeであれば 0 か 1、3項Treeであれば 0、1、2)を取り、Level[i+1] 上にある対応する Node インデックスを返します。その例を下記の図に示します。最後に、probability( )メソッドは、descendant( )メソッドと同じ引数を取り、対応するNodeへの分岐確率を返します。
当初の実装方法は、先ほどの Listing にあった Tree ベースクラスのような設計にしていました。それでも作動していましたが、数値計算プログラムとしては死に値するような罪を犯していました。この Tree ベースクラスでは、多重のループの中で何千回も呼び出されるようなメソッド (descendant( )やprobability( )メソッドなど)を、仮想関数として宣言していました。(注:なぜ、これが問題なのか分からない方は、簡単な説明の例として下記[1](Veldhuizen,2000)の文献を読んでみてください。) しばらくしてから、Short Rate Modelのカリブレーションに、小さな氷河が溶けるのを待つような時間がかかるのを見て、問題に気付きました。
その結果、実装をやり直すことにしました。その際、実行時における polymorphism(多相性)をコンパイル時の polymorphism に入れ替える為、Curiously Recurring Template Pattern(以下CRTP)を使い (このデザインパターンについて復習したい方は、このセクションの終わりにある <Aside> を読んで下さい)、その為に Treeクラスをテンプレートクラスとして、下記 Listing 7.7 のような実装に変更しました。ここでは、すべての仮想関数を取り除き、そうでない columns( )メソッドだけ残しています。このデザインパターンが動作する仕組みは、CuriouslyRecurringTemplate<T> のクラステンプレートにより提供されています。そこでは const と non-constバージョンの Impl( )メソッドを使って、同じ様なプログラムコードが反復するのを避けています。
Listing 7.7:Implementation of the Tree class template
template <class T>
class Tree : public CuriouslyRecurringTemplate<T> {
public:
Tree(Size columns) : columns_(columns) {}
Size columns() const { return columns_; }
private:
Size columns_;
};
これは設計のやり直しではありません。既存のクラス階層はそのまま残しました。次の 2項Tree と 3項Tree の説明の所で判ると思いますが、CRTPに転換する事で、やや複雑なプログラムコードになりました。しかし、計算速度の点では十分見返りがありました。新しい実装方法では、10倍程度までパフォーマンスの向上が見られました。その結果をみて、自分自身に対し、さらに多くの疑問をぶつけてみました (私自身も、問題の原因を作った者のひとりでしたので)。そうすると、コードをさらに単純化する機会を失っていたようです。冷静になって考えると、Treeのベースクラスが派生クラスで定義されたメソッドを呼び出していない事に気づくべきでした。そうすると、あえてCRTPを使わなくとも、単純な Template パターンでコードを単純化する事も可能でした。QuantLibライブラリーのデザインを見直す際に、覚えておかないといけない修正点です。
< Aside: Curiouser and Curiouser 「ますますおかしな事になってきたわ!」不思議の国のアリス >
Curiously Recurring Template Patternは、James Coplien の 1996年の彼の著作 (下記[2]参照) によって名付けられ有名になりましたが、そのデザイン自体は彼の著作以前から存在していました。このデザインは Template Method パターンを静的状態 (訳注:実行時ではなくコンパイル時) で構築する方法で、そこでは、ベースクラスが共通の動作を実装し、かつ派生クラスによって個別動作のために実装されたメソッドを、ベースクラスから呼び出すための hook(接続ポイント) を提供するものです。(下記[3]のGamma氏らの著作を参照)
その考え方をプログラムコードにすると、以下の様なものになります。
template <T>
class Base {
public:
T& impl() {
return static_cast<T&>(*this);
}
void foo() {
...
this->impl().bar();
...
}
};
class Derived : public Base<Derived> {
public:
void bar() { ... }
}; このコードで、“Derived”クラスのインスタンスを生成し、その foo( )メソッドを呼び出すと、結果的に派生クラスで実装された bar( )メソッドが呼び出される事になります(ベースクラスではbar( )メソッドを宣言していない事に注目して下さい)。 なぜこのような動作が行われるのか、コンパイラーで行われる作業を見ることによって理解する事ができます。“Derived”クラスでは foo( )メソッドを定義していませんので、ベースクラスから継承している事になります。すなわち Base<Derived> という Templateクラス として foo( )メソッドは、impl( )を呼び出します。impl( )は Base のインスタンスである *this (自分自身のポインター) を型変換して、Templateの引数の型 T 、すなわち ”Derived” クラスの参照に型変換します。そこで“Derived”のインスタンスが持つ bar( ) メソッドを呼び出しました。それは型変換がうまく行った事をしており、目的としていたオブジェクトへの参照を持つことができました。この時点で、コンパイラーは bar( )メソッドへの呼び出しを Derived::bar( ) への呼び出しとしてコンパイルするので、その結果、意図していたメソッドが呼び出される事になります。これらの動作はコンパイル時に行われ、コンパイラーは bar( )メソッドへの呼び出しを inline関数とみなし、それに応じた最適化を行います。
foo( )メソッドから直接 bar( ) を呼び出すのではなく、なぜこのような回りくどい方法を取るのでしょうか?それは単に foo から bar の呼び出しはうまく行かないからです。もしベースクラスで bar( )を宣言していなければ、コンパイラーは bar( )が何の事か判りません。逆に、もし宣言したとすると、コンパイラーは常にベースクラスの bar( )メソッドと理解してコンパイルしてしまいます。CRTP は、こういった不都合を回避させてくれます。bar( )メソッドを派生クラスでのみ定義し、Template の引数を使って派生クラスの型をベースクラスに渡し、static_cast を使ってベースクラスを派生クラスに型変換する事によって、循環がクローズされます。 (訳注:派生クラスのインスタンスから、ベースクラスを経由して、再び派生クラスのbar( )メソッドが呼び出せる。)
[1] T. Veldhuizen, Techniques for Scientific C++. Indiana University Computer Science Technical Report TR542.
[2] J.O. Coplien, A Curiously Recurring Template Pattern. In S.B. Lippman, editor, C++ Gems. Cambridge University Press, 1996.
[3] E. Gamma, R. Helm, R. Johnson and J. Vlissides, Design Patterns: Element of Reusable Object-Oriented Software. Addison-Wesley, 1995.
<ライセンス表示>
QuantLibのソースコードを使う場合は、ライセンス表示とDisclaimerの表示が義務付けられているので、添付します。 ライセンス