上級編 8 クレジットデリバティブズ
8.3 Gaussian Latent Variable Model (1 factor Gaussian Copula Model)
8.3.4 価格評価アルゴリズム
8.3.4.3 ポートフォリオの損失率の条件付き同時確率分布を求める(Recursion法)
(Section 8.3.3.1-⑤のプロセス)
次に、ポートフォリオ全体から発生するデフォールト数の条件付き同時確率分布関数を求めます。前のセクションで示した 8.4 式を、個別銘柄の条件付き周辺確率分布関数とし、それらの組み合わせで同時確率分布関数を求めます。ここが、全体のアルゴリズムの中で、最も計算量が多い部分です。
さて、ここで、デフォールト数の確率分布を求めると言いましたが、実際に求めたいのはデフォールトによる損失率の確率分布です。後々、CDOの各トランチの期待損失率カーブを導出する必要がありますが、そこで必要となる情報は、デフォールト数ではなく、デフォールト損失率の同時確率分布だからです。とは言っても、ここで紹介するアルゴリズムは、基本的にデフォールト数であってもデフォールト損失率であってもアルゴリズムは全く同じです。以下に2項ツリーを使ったアルゴリズムを示しますが、ツリーの各ノードをデフォールト数のノードと考えるか、デフォールト損失率のノードと考えるかの違いです。
さて、ある将来の時点Tまでに、ポートフォリオから発生するデフォールト損失率は、下記式で表せます。この式は、T 時までにデフォールトした銘柄の損失率の総和になっています。
\[ L(T) =\sum_{i=1}^N F(1-R_i)∙I_{τ_i \lt T } ~~~~~~~~~~~~~~~~~~~~~~~~ \tag{8.20} \] 但し
\(F\) : ポートフォリオ中の各銘柄の構成比。通常 1/N
(銘柄ごとの構成比が異なるケースも偶にあるが、ここではすべて同一と仮定)
\(R_i\) : 各銘柄の債権回収率。
\(τ_i\) : i番目の銘柄がデフォールトした時間
\(I_{τ_i < T}\) : 指示関数。i がデフォールトした場合は 1、それ以外は 0 を返す。
上の式では、銘柄ごとに債権回収率が異なる前提で、それを \(R_i,~~i=1,...,N\) と置いています。しかし、債権回収率は、銘柄の所属する業種や国によって大きく異なるし、それがローンか債券かでもかなり違います。それらを個別銘柄ごとに予想するのは非常に難しく、何等かのモデルを使っても、あまりあてになりません。なので、実務ではすべての銘柄で同一の債権回収率を使い、その率として40%を使うケースが多いようです。
F についてですが、CDX や iTraxx インデックスを対象とした場合、N=125 で、すべての銘柄が均等に構成されているので、F=1/125=0.008 となります。すなわち、ポートフォリオの中で1銘柄が占める比率は 0.8% という事です。それに 1-R=1-0.4=0.6 を掛けると、1銘柄あたりの損失率は、ポートフォリオ全体のみなし元本の 0.48% になります。それを損失の1単位として u と置きます。すると8.19 式の \(L(T)\) は、ポートフォリオのみなし元本に対する損失率に相当し、それは u の整数倍で表せます。すなわち、ここで求めようとしているのは、損失率が 0,u,2u,3u,…,125u=0.6 となる、離散的な確率分布です。まず有り得ませんが、仮にすべての銘柄がデフォールトしたとしても、損失率の最大値は 60% です。なので損失率が 60% から 100% の間になる確率は 0 です。
ここから、各損失率(0,u,2u,3u,…125u)に対応する確率を求める手順は以下のようになります(注:以下の解説は、Dominic O‘Kane“Modelling … Credit Derivatives ” Wiley Finance Seriesを参考にしています。)
(1) 個別銘柄 i について、市場ファクター M を特定の値 m に固定した場合の条件付きデフォールト確率は、確率変数 \(ϵ_i\) のデフォールト閾値と分布関数を使って、下記のように求まっていました(8.5式)。 \[ P_i \left( ϵ_i \lt \frac{D_i (T)-β~m}{\sqrt{1-β^2}}~|~M=m\right) = \Phi \left(\frac{D_i(T)-β~m}{\sqrt{1-β^2}} \right),~~~i=1,…,125 \tag{8.5} \] これを周辺確率分布とし、N 個の銘柄中、k 個の銘柄がデフォールトする同時確率分布関数を求めます。ここで、銘柄 i のサバイバル確率を \(Q_i(T)\) と置くと、 \[ P_i (…|M=m)= \Phi \left(\frac{D_i(T)-β~m}{\sqrt{1-β^2} } \right)= 1-Q_i(T) \] と表記できます。以下の説明では個別銘柄のデフォールト確率を \(1-Q_i(T)\)、サバイバル確率を \(Q_i(T)\) として進めます。
(2) 既に Vasicek のモデルの所で述べましたが、N 個から k個のデフォールト銘柄を選択する組み合わせは \(\frac{N!}{(N-k)!k!}\) 通りあり、本来なら、それぞれについて同時確率分布関数を求める必要があります。周辺確率分布関数から同時確率分布を求めるには、普通なら深度が N の多重積分が必要ですが、これだけの数の多重積分をそれぞれ求めるのはほぼ不可能です。しかし、各個別ファクター \(ϵ_i\) が独立なので多重積分は必要なく、組み合わせごとに、個別のデフォールト確率とサバイバル確率の総積で求まります。それを \(\frac{N!}{(N-k)!k!}\) 通り計算する必要がありますが、それも二項ツリーを使えば、計算の手間が大幅に低減され、非常に小さな計算負荷(と言ってもツリーのノード数の数だけ計算が必要ですが)で求める事ができます。
(3) 以下に2項ツリーの概要を図示します。損失率の分布は、離散的で 0 から 125u まであります。1銘柄ずつ順番に、デフォールトしたか否かを場合分けし、最終的に 0 から 125u までの損失率それぞれに到達する確率を計算します。スタートとして、ポートフォリオから最初の 1 銘柄を選択します。それがデフォールトしていれば損失率は u となり、デフォールトしていなければ損失率は 0 です。それぞれへの到達確率は\( 1-Q_1 (T)~と~Q_1(T)\) になります。次に、このポートフォリオからもう1銘柄選択し、それがデフォールトしたか否か判定します。2銘柄のポートフォリオから発生する損失率は 0,1u,2u のいずれかです。それぞれの到達確率は以下のように求まります。
\[ \begin{eqnarray}
\begin{cases}
2u~~~& (1-Q_1(T))(1-Q_2(T)) \\
1u~~~& (1-Q_1(T))Q_2 (T)~~~~~+~~Q_1(T)(1-Q_2(T)) \\
0~~~~& Q_1 (T) Q_2(T)
\end{cases}
\end{eqnarray}
\]
要は、2項ツリーの経路に従って、各ノードへの到達確率を、順番に計算します。
これに、3銘柄、4銘柄と順番に加えて行き(すると損失単位として 3u, 4u が加わって行きます)、これを 125銘柄で繰り返します。すると、125銘柄からなるポートフォリオから発生する損失率は、0,u,…,125u のいずれかになり、それぞれの確率求まります。下の図の 125 番目のノードの確率が損失分布の確率になります。
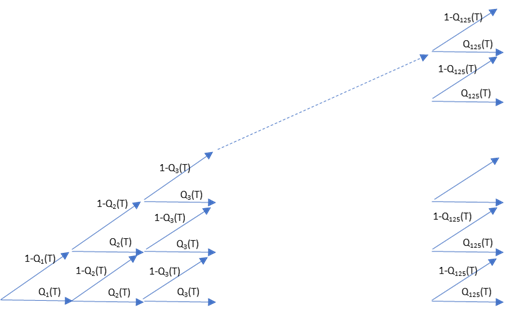
(4) 上の2項ツリーの最終ノードは、損失率が 0 から 125u までの、離散的な条件付き同時確率分布になります。各ノードの状態変数を損失率(uの整数倍)ではなく、デフォールト数(0 から 125 までの整数)とすれば、デフォールト数の確率分布でもあります。最終ノード ku, k=0,...,N の到達経路数は、\(\frac{N!}{(N-k)!k!}\) 通り あり、N 個のポートフォリオから k 個のデフォールト銘柄を選択する組み合わせの数と同じです。最終ノードでの確率は、それらの経路ごとの確率をすべて足し合わせた値になっています。本来なら、何百兆、何千兆通りの組み合わせでそれぞれの確率を計算する必要がありますが、この2項ツリーのアルゴリズムでは、それが \(N^2=125^2\) のオーダーでの計算量で済みます。
(注:\(\frac{N!}{(N-k)!k!}\) は、N=125, k=62 で最大となり、その数は約 \(3×10^{36}\) となります。これは通常のコンピューターの計算能力を遥かに超える数です。)
但し、これはあくまで M=m の条件付き確率になるので、ここから、無条件の同時確率分布関数を求めます。その為には、M の範囲にあるすべての m について上記の2項ツリーでの確率分布を求める必要があります。では次に、この無条件の同時確率分布関数を求める方法を説明します。